Docker 网络配置
端口映射
容器中可以运行一些网络应用,要让外部也可以访问这些应用,可以通过 -P 或 -p 参数来指定端口映射。
当使用 -P 标记时,Docker 会随机映射一个端口到内部容器开放的网络端口。
-p 则可以指定要映射的端口,并且,在一个指定端口上只可以绑定一个容器,支持的格式有 ip:hostPort:containerPort | ip::containerPort | hostPort:containerPort。
419bb2720cc1 nginx:alpine "/docker-entrypoint.…" 34 hours ago Up 34 hours 0.0.0.0:50->80/tcp本地主机的 50 被映射到了容器的 80 端口。此时访问本机的 50 端口即可访问容器内 NGINX 默认页面。
同样的,可以通过 docker logs 命令来查看访问记录。
映射所有接口地址
使用 hostPort:containerPort 格式本地的 80 端口映射到容器的 80 端口,可以执行
docker run -d -p 80:80 nginx:alpine此时默认会绑定本地所有接口上的所有地址。
映射到指定地址的指定端口
可以使用 ip:hostPort:containerPort 格式指定映射使用一个特定地址,比如 localhost 地址 127.0.0.1
docker run -d -p 127.0.0.1:80:80 nginx:alpine映射到指定地址的任意端口
使用 ip::containerPort 绑定 localhost 的任意端口到容器的 80 端口,本地主机会自动分配一个端口。
docker run -d -p 127.0.0.1::80 nginx:alpine还可以使用 udp 标记来指定 udp 端口
docker run -d -p 127.0.0.1:80:80/udp nginx:alpine查看映射端口配置
使用 docker port 来查看当前映射的端口配置,也可以查看到绑定的地址
docker port nginx:alpine 80
# 0.0.0.0:50注意:
- 容器有自己的内部网络和 ip 地址(使用
docker inspect查看,Docker 还可以有一个可变的网络配置。) -p标记可以多次使用来绑定多个端口
容器互联
新建网络
创建一个新的 Docker 网络。
docker network create -d bridge my-net-d 参数指定 Docker 网络类型,有 bridge overlay。
连接容器
运行一个容器并连接到新建的 my-net 网络
docker run -it --rm --name busybox1 --network my-net busybox sh打开新的终端,再运行一个容器并加入到 my-net 网络
docker run -it --rm --name busybox2 --network my-net busybox sh再打开一个新的终端查看容器信息
docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
b47060aca56b busybox "sh" 11 minutes ago Up 11 minutes busybox2
8720575823ec busybox "sh" 16 minutes ago Up 16 minutes busybox1下面通过 ping 来证明 busybox1 容器和 busybox2 容器建立了互联关系。
在 busybox1 容器输入以下命令
ping busybox2
PING busybox2 (172.19.0.3): 56 data bytes
64 bytes from 172.19.0.3: seq=0 ttl=64 time=0.072 ms
64 bytes from 172.19.0.3: seq=1 ttl=64 time=0.118 ms用 ping 来测试连接 busybox2 容器,它会解析成 172.19.0.3。
同理在 busybox2 容器执行 ping busybox1,也会成功连接到。
/ # ping busybox1
PING busybox1 (172.19.0.2): 56 data bytes
64 bytes from 172.19.0.2: seq=0 ttl=64 time=0.064 ms
64 bytes from 172.19.0.2: seq=1 ttl=64 time=0.143 ms这样,busybox1 容器和 busybox2 容器建立了互联关系。
如果你有多个容器之间需要互相连接,推荐使用 Docker Compose。
配置 DNS
Docker 通过挂载虚拟文件来管理容器的网络配置文件:
/etc/hostname:容器主机名/etc/hosts:主机名与 IP 的映射/etc/resolv.conf:DNS 服务器配置
这些文件与宿主机关联,因此宿主机的 DNS 更新可自动同步到容器中。
全局配置(影响所有容器)
在宿主机的 /etc/docker/daemon.json 文件中添加:
{
"dns": ["114.114.114.114", "8.8.8.8"]
}重启 Docker 服务后,所有新启动的容器都会自动使用该 DNS。
验证命令:
docker run -it --rm ubuntu:18.04 cat /etc/resolv.conf单独配置(影响某个容器)
在 docker run 时指定参数:
| 参数 | 作用 |
|---|---|
-h 或 --hostname=HOSTNAME | 设置容器主机名(写入 /etc/hostname 和 /etc/hosts) |
--dns=IP_ADDRESS | 指定容器使用的 DNS 服务器(写入 /etc/resolv.conf) |
--dns-search=DOMAIN | 设置搜索域(如 --dns-search=example.com 会解析 host 为 host.example.com) |
如果不指定 --dns 或 --dns-search,Docker 默认会继承宿主机的 /etc/resolv.conf。
总结:Docker 通过挂载虚拟文件 /etc/hostname、/etc/hosts、/etc/resolv.conf 实现容器主机名和 DNS 配置。
可通过 全局配置文件 设置所有容器的 DNS,也可在 docker run 时为单个容器手动指定。
高级网络配置
Docker 安装后,会自动创建几个默认网络:
| 网络名 | 类型 | 说明 |
|---|---|---|
bridge | 桥接网络 | 默认网络,容器间用 IP 通信 |
host | 主机网络 | 直接使用宿主机网络,无隔离 |
none | 无网络 | 完全断网模式 |
| (用户自定义的) | 桥接或其他类型 | 最推荐的实践方式 |
默认 bridge 网络虽然方便,但容器名无法直接互相解析(要用 IP),而 自定义 bridge 网络 则支持容器名自动 DNS 解析,非常方便。
什么是网桥
想象一下一个办公室里有多台电脑:
- 每台电脑都有自己的网线(网卡);
- 它们都插在同一个交换机上;
- 交换机会在电脑之间转发数据,让它们能互相通信。
在网络世界里,这个 交换机 的角色,就是“网桥(bridge)”。
网桥的作用:连接多个网络接口,让它们像在同一个局域网里一样通信。
在传统 Linux 网络中:
- 物理网卡(eth0) 负责与外界通信;
- 虚拟网桥(bridge) 是一个虚拟交换机;
- 虚拟网卡(veth pair) 是桥与容器之间的“网线”。
可以这样理解结构:
[容器A eth0]──┐
│
[veth pair]──[br0]──[宿主机 eth0]──Internet
│
[容器B eth0]──┘br0(或 Docker 默认的 docker0)就是 Linux 网桥设备,它让所有挂上去的容器像在同一个交换机里一样互通。
当你安装 Docker 时,它默认会创建一个虚拟网桥:
docker0: 172.17.0.1/16然后,每当你运行一个容器:
- Docker 会创建一对虚拟网卡(
veth); - 一端放进容器(当作容器的
eth0); - 另一端连接到
docker0网桥。
于是容器获得一个虚拟 IP,比如:
172.17.0.2多个容器都挂到同一个 docker0 上,于是它们能互相通信,而且通过 NAT(iptables)规则,也能访问外网。
查看宿主机的网桥:
brctl show输出示例:
bridge name bridge id STP enabled interfaces
docker0 8000.0242ac110002 no veth12345说明:
bridge name 是虚拟网桥;
interfaces 是接入桥的虚拟网卡(即连接的容器)。
网桥(bridge) 是一种让多个虚拟或物理网卡组成同一局域网的网络设备。在 Docker 中,它就像一个虚拟交换机,负责让容器之间互相通信。
| 类型 | 特点 | 通信路径 |
|---|---|---|
bridge(默认) | 所有容器连接到宿主机的虚拟网桥 docker0 | 容器 → docker0 → 宿主机网卡 → 公网 |
自定义 bridge | 创建自定义子网(如 172.18.0.0/16) | 容器 → my-bridge → docker0 → 宿主机网卡 |
overlay(Swarm 或跨主机网络) | 在多个主机之间创建虚拟子网 | 容器 → overlay 子网 → VXLAN 隧道 → 另一主机网桥 |
macvlan | 容器直接“拥有”宿主机的物理网卡 MAC 地址 | 容器 → 物理网络(绕过网桥) |
也就是说,容器可能:
- 直接连接默认网桥(docker0);
- 连接到一个自定义 bridge 子网(桥连在桥上);
- 甚至跨宿主机通过 overlay 网络连接。
但无论哪种情况,最终访问外网时,都会经由宿主机的物理网络接口(eth0、ens33 等)转发出去
总结:容器的所有网络流量最终都会经过宿主机的虚拟网桥(bridge)与物理网卡转发出站。即使存在自定义子网或多层网络,它们本质上仍通过宿主机网络访问外部世界。
Overlay 网络 是 Docker 提供的一种虚拟网络技术,用于 在多个宿主机之间创建一个逻辑上的虚拟局域网(VLAN 类似,但更灵活)。
可以把它理解为:比子网更高级的虚拟局域网,可以跨宿主机,把多个 Docker 主机上的容器看作同一个网络段里的机器。
原理
Overlay 网络会在宿主机之间创建 隧道(VXLAN):
- 容器的流量先从容器 veth 进入本机的 overlay 网桥;
- 再封装成 VXLAN 包,通过宿主机物理网络发送到其他宿主机;
- 到达目标宿主机解封装,再进入目标容器。
容器间可以直接通过容器名互相访问,就像在同一个局域网里一样。
与自定义子网(bridge)对比
| 特性 | 自定义 bridge | Overlay |
|---|---|---|
| 作用范围 | 单宿主机 | 多宿主机 / 集群 |
| 连接方式 | 容器 → 网桥 → 宿主机 → NAT / 物理网 | 容器 → overlay 虚拟网 → VXLAN → 另一宿主机容器 |
| 容器名解析 | 内建 DNS(单宿主机) | 内建 DNS(跨主机集群) |
| 出站 NAT | 容器访问外网需要 NAT | 容器访问外网通常由宿主机 NAT |
| 应用场景 | 单机开发、测试 | Swarm/Kubernetes 集群、跨主机服务通信 |
| 复杂度 | 简单 | 高,需要集群控制平面支持 |
可以理解为:bridge 是局部局域网,overlay 是跨宿主机的“虚拟局域网”。
Overlay 的实际用途
Docker Swarm / Kubernetes 集群
- 让不同宿主机上的服务容器互联,就像在同一个局域网;
- 支持容器名解析(service name)和自动负载均衡。
微服务架构
- 不管容器在集群哪个节点,都可以通过逻辑网络访问服务;
- 解决跨主机通信问题。
跨数据中心 / 私有云
- 可以在物理网络不互通的情况下,通过 overlay 隧道互联容器。
Overlay 与自定义子网结合使用
在 overlay 网络内部,每个服务或容器依然会有自己的子网(比如 10.0.0.0/24、10.0.1.0/24);
你可以理解成:
- Overlay = “跨宿主机的虚拟交换机”
- 子网 = “交换机内部划分的小网络段”
总结:Overlay 网络 = 更高级的虚拟局域网,用于跨宿主机容器通信,通常用于集群环境,而自定义子网(bridge)只限于单宿主机。
注
单宿主机自定义子网(Custom Bridge)
特点:
范围:仅限当前宿主机。
容器名解析:支持。容器 A 可以通过容器名访问容器 B。
通信机制:
容器 → veth → 自定义 bridge → 宿主机 → 容器外网访问:通过宿主机 NAT。
用途:单机开发、测试、轻量部署。
换句话说,它是一个 局域网,容器间通信完全没问题,但只局限在一台宿主机上。
注
Overlay 网络(跨宿主机自定义子网)
特点:
范围:可以跨多台宿主机。
容器名解析:支持。无论容器在哪台宿主机,都能通过服务名访问。
通信机制:
容器 → veth → overlay 网桥 → VXLAN 隧道 → 另一宿主机 overlay → 目标容器外网访问:依然通过宿主机 NAT。
用途:Swarm / Kubernetes / 集群微服务。
Overlay 网络可以把不同宿主机上的容器逻辑上放到同一个局域网里,所以才适合集群环境。
为什么单宿主机自定义子网不能直接“集群化”
- 单宿主机的 bridge 网络,只能管理当前主机的 veth 对接和 IP 分配。
- 如果你把 bridge 网络跨宿主机直接用,没有 VXLAN 或类似隧道,宿主机之间根本不知道对方网络存在。
- 容器名解析和路由只在本地主机生效,跨宿主机无法自动解析。
所以 桥接子网可以在单机里实现容器名通信,但要跨机器就必须 overlay 或类似的隧道技术。
自定义子网是单宿主机级别的“虚拟局域网”,Overlay 是跨宿主机的“虚拟局域网+隧道”,前者方便本地通信,后者适合集群环境。
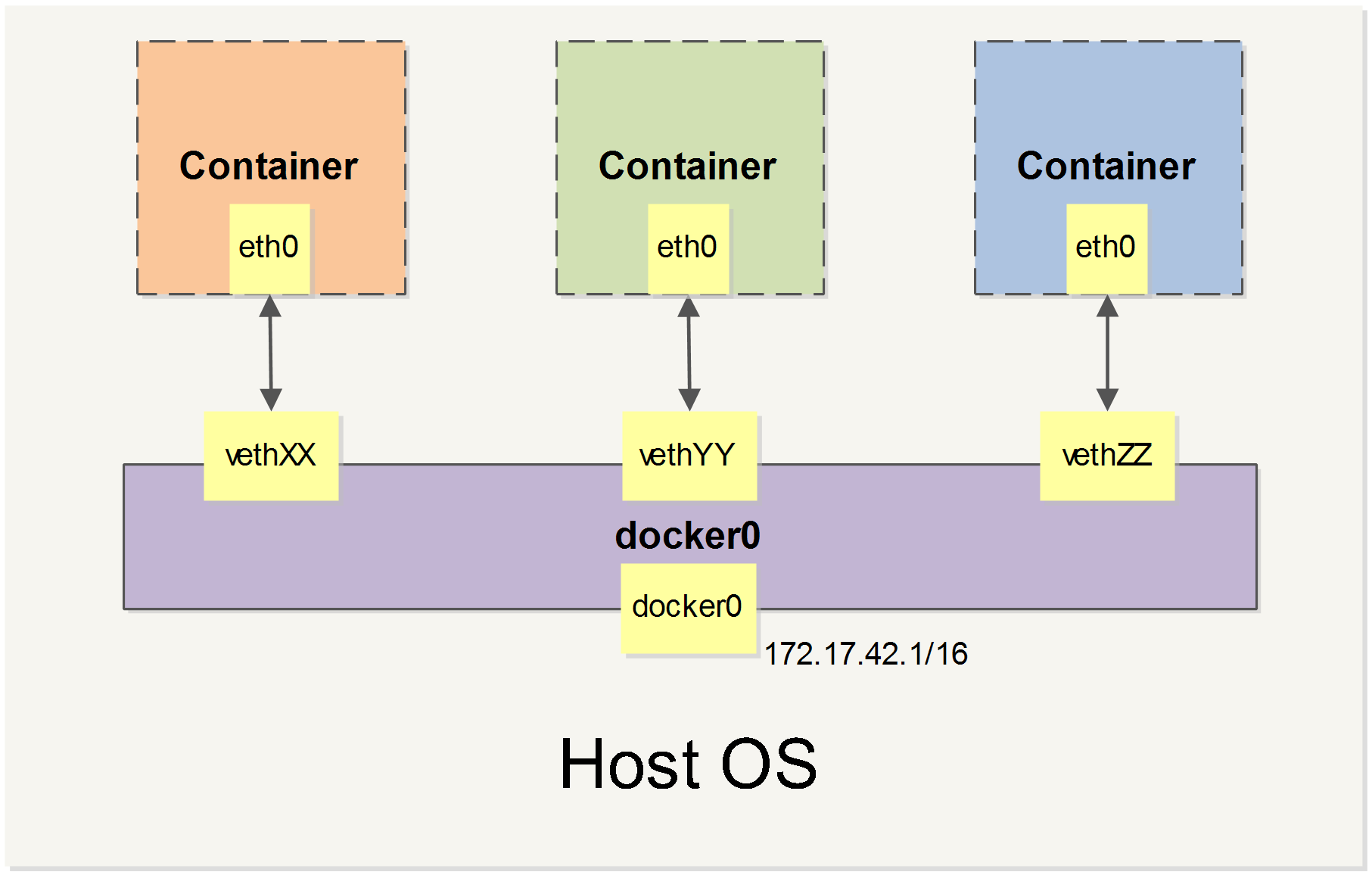
当 Docker 启动时,会自动在主机上创建一个 docker0 虚拟网桥,实际上是 Linux 的一个 bridge,可以理解为一个软件交换机。它会在挂载到它的网口之间进行转发。
同时,Docker 随机分配一个本地未占用的私有网段中的一个地址给 docker0 接口。比如典型的 172.17.42.1,掩码为 255.255.0.0。此后启动的容器内的网口也会自动分配一个同一网段(172.17.0.0/16)的地址。
当创建一个 Docker 容器的时候,同时会创建了一对 veth pair 接口(当数据包发送到一个接口时,另外一个接口也可以收到相同的数据包)。
这对接口一端在容器内,即 eth0;另一端在本地并被挂载到 docker0 网桥,名称以 veth 开头(例如 vethAQI2QT)。
通过这种方式,主机可以跟容器通信,容器之间也可以相互通信。Docker 就创建了在主机和所有容器之间一个虚拟共享网络。
相关命令
其中有些命令选项只有在 Docker 服务启动的时候才能配置,而且不能马上生效。
-b BRIDGE或--bridge=BRIDGE指定 Docker 容器挂载的默认网桥,例如 docker0 或自定义桥接网络。所有新建容器默认连接到这个网桥。--bip=CIDR设置 docker0 网桥的 IP 地址和子网掩码。例如--bip=172.18.0.1/16,用于容器分配 IP。-H SOCKET...或--host=SOCKET...指定 Docker 服务端监听的通道,可以是 Unix Socket 或 TCP Socket,用于接受 Docker CLI 或 API 命令。--icc=true|false是否支持容器之间进行通信--ip-forward=true|false允许你的宿主操作系统内核转发网络流量,如果没有开启 IP 转发,容器将无法“走出去”(访问互联网)或“走进来”(通过端口映射被访问)。Docker 通常会默认启用它。--iptables=true|false是否允许 Docker 添加 iptables 规则--mtu=BYTES设置容器网络接口的最大传输单元(MTU),用于优化网络性能或兼容隧道。
下面 2 个命令选项既可以在启动服务时指定,也可以在启动容器时指定。在 Docker 服务启动的时候指定则会成为默认值,后面执行 docker run 时可以覆盖设置的默认值。
--dns=IP_ADDRESS...指定容器使用的 DNS 服务器 IP,可在 daemon 设置默认,也可在单容器启动时覆盖。--dns-search=DOMAIN...设置容器的 DNS 搜索域,例如example.com,用于解析短域名。
最后这些选项只有在 docker run 执行时使用,因为它是针对容器的特性内容。
-h HOSTNAME或--hostname=HOSTNAME设置容器内部的主机名,写入容器的/etc/hostname和/etc/hosts。--link=CONTAINER_NAME:ALIAS将当前容器与另一个容器建立连接,使容器可以通过别名互相访问(已被自定义网络和 overlay 网络替代)。--net=bridge|none|container:NAME_or_ID|host配置容器的桥接模式-p SPEC或--publish=SPEC映射容器端口到宿主机端口,例如-p 8080:80表示宿主机 8080 映射到容器 80 端口。-P or --publish-all=true|false映射容器所有端口到宿主主机
容器访问控制
在 Linux 容器(如 Docker、Podman)中,容器的网络访问控制主要依赖 Linux 内核的防火墙机制,通常是 iptables 或现代系统上的 nftables。具体说明:
iptables 是默认防火墙
- Linux 内核自带
iptables,大部分发行版默认安装。 - 它通过 规则链(chains)和表(tables) 控制网络流量,可以过滤入站、出站、转发的数据包。
- 容器启动时,Docker 等容器引擎会自动在
iptables上创建规则,实现 NAT 转发、端口映射、网络隔离。
容器访问控制的实现方式
- NAT(网络地址转换):通过
iptables的nat表,将容器内部端口映射到宿主机端口。 - 网络隔离:容器默认使用独立的网络命名空间,配合
iptables规则限制容器间或容器与外部的通信。 - 端口/流量控制:可以通过自定义
iptables规则限制哪些 IP 或端口可以访问容器。
现代替代方案
- 新版本 Linux 偏向使用
nftables,Docker 也在逐步支持。 - 上层工具如
firewalld或ufw也能管理容器访问规则,但容器引擎通常直接操作底层防火墙。
容器要想访问外部网络,需要本地系统的转发支持。在Linux 系统中,检查转发是否打开。
简而言之:容器的访问控制依赖 Linux 内核提供的防火墙功能,iptables 是最常用的默认工具,容器引擎会在其上自动配置规则来实现端口映射和网络隔离。
容器访问外部网络的条件
网络命名空间隔离
- 容器通常运行在独立的网络命名空间中,拥有自己的 IP 地址和网络栈。
- 默认情况下,这个网络命名空间和宿主机外部网络是隔离的。
需要宿主机进行 IP 转发
- 容器访问外部网络(如互联网)时,宿主机需要将容器的流量 路由转发 到外部网络。
- Linux 内核通过 IP 转发功能 控制这一行为。
检查或开启 IP 转发
- 查看当前状态:
sysctl net.ipv4.ip_forward
# net.ipv4.ip_forward = 1返回 1 表示开启,0 表示关闭。
- 临时开启:
sysctl -w net.ipv4.ip_forward=1永久开启(重启后仍生效):编辑 /etc/sysctl.conf,添加或修改:
net.ipv4.ip_forward = 1然后执行:
sysctl -p结合防火墙实现 NAT
- 容器引擎(如 Docker)通常会在宿主机
iptables上添加 MASQUERADE/NAT 规则,把容器流量映射到宿主机的公网 IP。 - 有了 IP 转发和 NAT,容器就可以访问外部网络,同时保持容器内网地址独立。
总结一句话:容器访问外部网络必须依赖宿主机的 IP 转发,可以通过 sysctl net.ipv4.ip_forward 检查和开启;结合防火墙 NAT 规则,实现容器网络与外部网络的通信。
一般情况下 官方的 Docker 安装脚本 或者通过官方包安装 Docker 时,会自动开启 IP 转发(net.ipv4.ip_forward=1),以确保容器可以访问外部网络。
通常你不需要手动去开启这个参数,除非你做了自定义内核网络设置或者禁用了 Docker 的默认配置。
容器之间访问
容器要互相访问(比如容器 A 访问容器 B 的服务),需要满足两个条件:
- 网络拓扑允许通信
- 宿主机防火墙允许通信
容器网络拓扑(Topology)
什么是网络拓扑?
- 拓扑就是网络中设备之间的连接关系。
- 对容器来说,拓扑决定了容器是否在同一个网络里,以及它们之间能否直接通信。
Docker 的默认网络拓扑
Docker 安装后,会创建一个默认网桥 docker0:
- 这是宿主机上的一个虚拟网桥(类似交换机)。
- 默认情况下,所有新建的容器都会连接到
docker0。 - 容器会分配一个私有 IP(比如 172.17.0.x),在同一网桥内,容器之间可以互相访问。
拓扑的类型
Docker 支持几种网络模式,每种模式的拓扑不同:
| 模式 | 描述 | 容器互访情况 |
|---|---|---|
| bridge(默认) | 容器连接到宿主机上的虚拟网桥 docker0 | 同一桥内可互访,不同桥默认隔离 |
| host | 容器共享宿主机网络栈 | 容器可以直接访问宿主机网络,也可访问宿主机的其他服务 |
| overlay | 跨主机容器互联 | 用于 Swarm 集群,跨物理机通信 |
| none | 容器没有网络接口 | 容器之间无法通信 |
所以,默认情况下,容器在同一个 docker0 网桥里,拓扑上是互联的。
防火墙的影响(iptables)
即使网络拓扑允许,宿主机防火墙也可能阻止容器间通信。
Docker 启动时,会在宿主机的 iptables 中添加规则:
- 允许同一桥接网络的容器之间互相访问。
- 实现端口映射和 NAT。
如果你手动配置了防火墙或禁用了 Docker 的 iptables 规则,容器之间的互访可能会被阻止。
检查方法:
# 查看 docker0 网桥
ip addr show docker0
# 查看容器之间的防火墙规则
sudo iptables -L -v -n容器互访示意流程
- 容器 A 发起访问 → 目标 IP 是容器 B 的私有 IP。
- 数据包通过 docker0 网桥转发到容器 B。
- iptables 规则检查是否允许 → 允许则通过,阻止则丢弃。
- 数据到达容器 B,通信完成。
总结
- 拓扑决定容器能否在逻辑上互联,默认
docker0网桥允许同桥容器互访。 - 防火墙决定数据包能否被宿主机允许通过。
- Docker 默认配置下,容器可以互访,不需要额外操作;自定义网络或严格防火墙时,需要注意规则配置。
访问指定端口
在 Docker 中,即使关闭了容器之间的默认网络访问(通过 -icc=false),仍然可以通过 --link 选项访问指定容器的开放端口。
启动 Docker 服务时,可以使用参数:
dockerd --icc=false --iptables=trueicc=false:禁止容器间默认相互访问
--iptables=true:允许 Docker 修改宿主机的 iptables 规则
此时,宿主机默认的 iptables 规则可能类似:
Chain FORWARD (policy ACCEPT)
target prot opt source destination
DROP all -- 0.0.0.0/0 0.0.0.0/0默认拒绝容器之间的通信。
使用 --link 实现访问,启动容器时使用:
docker run --link CONTAINER_NAME:ALIAS ...CONTAINER_NAME:目标容器的名字(Docker 自动分配或通过 --name 指定)
ALIAS:在当前容器内使用的别名
Docker 会在 iptables 中自动添加规则,只允许两个容器之间的指定端口互访(通常基于 Dockerfile 中的 EXPOSE 指令),例如:
Chain FORWARD (policy ACCEPT)
target prot opt source destination
ACCEPT tcp -- 172.17.0.2 172.17.0.3 tcp spt:80
ACCEPT tcp -- 172.17.0.3 172.17.0.2 tcp dpt:80
DROP all -- 0.0.0.0/0 0.0.0.0/0这样,即使默认禁止容器间通信,使用 --link 的容器仍可以通过指定端口互相访问。
注意
--link中的 CONTAINER_NAME 必须是 Docker 分配的容器名,或者通过--name指定的名字。- 容器的主机名不会被识别。
--link是一种显式允许访问的方式,适合精确控制容器间通信,而不依赖默认桥接网络。
总结:
- 默认情况下,
-icc=false禁止容器互访。 - 使用
--link=CONTAINER_NAME:ALIAS可以在 iptables 上为两个容器添加规则,只允许指定端口互访。 - 这种方式结合了安全隔离与可控访问,适用于需要严格网络策略的场景。
这个机制的核心就是 严格控制容器之间的访问:
- 默认情况下,Docker 容器在同一个桥接网络上可以互相访问。
- 使用
-icc=false可以关闭这种默认互访,让容器之间不能随意通信。 - 之后,如果某些容器需要通信,可以用
--link=CONTAINER_NAME:ALIAS显式允许,只开放指定端口。
换句话说:这是为了实现“最小权限”原则:默认禁止容器之间互访,只允许明确授权的端口通信,从而提升安全性,防止容器之间随意访问或泄露服务。
这种方式特别适合 多租户环境 或 敏感服务部署,每个容器的网络访问都被严格控制。
映射容器端口到宿主主机的实现
默认情况下,容器可以主动访问到外部网络的连接,但是外部网络无法访问到容器。
容器访问外部实现
容器所有到外部网络的连接,源地址都会被 NAT 成本地系统的 IP 地址。这是使用 iptables 的源地址伪装操作实现的。
查看主机的 NAT 规则。
sudo iptables -t nat -nL
...
Chain POSTROUTING (policy ACCEPT)
target prot opt source destination
MASQUERADE all -- 172.17.0.0/16 !172.17.0.0/16
...其中,上述规则将所有源地址在 172.17.0.0/16 网段,目标地址为其他网段(外部网络)的流量动态伪装为从系统网卡发出。MASQUERADE 跟传统 SNAT 的好处是它能动态从网卡获取地址。
外部访问容器实现
容器允许外部访问,可以在 docker run 时候通过 -p 或 -P 参数来启用。
不管用那种办法,其实也是在本地的 iptable 的 nat 表中添加相应的规则。
使用 -P 时:
iptables -t nat -nL
...
Chain DOCKER (2 references)
target prot opt source destination
DNAT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:49153 to:172.17.0.2:80使用 -p 80:80 时:
iptables -t nat -nL
Chain DOCKER (2 references)
target prot opt source destination
DNAT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:80 to:172.17.0.2:80注意:
- 这里的规则映射了
0.0.0.0,意味着将接受主机来自所有接口的流量。用户可以通过-p IP:host_port:container_port或-p IP::port来指定允许访问容器的主机上的 IP、接口等,以制定更严格的规则。 - 如果希望永久绑定到某个固定的 IP 地址,可以在 Docker 配置文件
/etc/docker/daemon.json中添加如下内容。
{
"ip": "0.0.0.0"
}在 Linux 的 iptables 中,nat 表并不是单个规则,而是一个独立的表(table),里面可以有很多规则和链(chain),所以 NAT 可以有多个,而不是只能一个。具体说明如下:
iptables NAT 的概念
NAT(Network Address Translation):网络地址转换,用来修改数据包的源地址或目标地址,实现容器/私网访问外网或端口映射。
iptables 中的 NAT 表:
- 专门用于处理数据包地址转换的表
- 内置三个主要链(chains):
- PREROUTING:数据包进入前处理,常用于 DNAT(目标地址转换)
- POSTROUTING:数据包离开前处理,常用于 SNAT/MASQUERADE(源地址转换)
- OUTPUT:本机发出的包处理 NAT
多个 NAT 规则
在 同一个 NAT 表里,可以添加多条规则。
例如,你可以同时有:
- 容器 A 的 80 端口映射到宿主机 8080 - 容器 B 的 443 端口映射到宿主机 8443这些都是 NAT 表里的不同规则。
每条规则针对不同源/目标 IP 或端口,可以共存。
表和链的关系
nat 表
├─ PREROUTING (DNAT)
├─ POSTROUTING (SNAT/MASQUERADE)
└─ OUTPUT- 表 = 一个容器或系统中处理 NAT 的整体逻辑
- 链 = NAT 表内不同处理阶段
- 规则 = 链内的每条具体操作
- 所以 NAT 可以是 多个规则,统一在 nat 表 内管理
规则解析
Chain DOCKER (2 references)
target prot opt source destination
DNAT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:80 to:172.17.0.2:80Chain DOCKER:Docker 在 nat 表中创建的自定义链,用来管理容器端口映射规则
DNAT:目标地址转换(Destination NAT)
- 把目标 IP/端口从宿主机地址转换到容器内部 IP/端口
tcp dpt:80 to:172.17.0.2:80:
- 任何访问宿主机 80 端口 的 TCP 流量
- 都会被转发到容器 IP
172.17.0.2的 80 端口
为什么容器可以被外部访问
- 外部访问宿主机的 80 端口 → iptables 检测到 DNAT 规则 → 转发到容器 80 端口 → 容器处理请求 → 返回流量通过宿主机 NAT 返回客户端
- 这个机制也叫 端口映射(port mapping),Docker 启动容器时使用
-p或--publish就会自动创建这样的规则。
为什么容器可以访问外部
- 除了 DNAT 规则外,Docker 会在
POSTROUTING链添加 MASQUERADE/SNAT 规则,把容器流量的源地址改成宿主机的 IP - 这样返回的数据包可以正确回到容器,实现 容器访问外网
总结
总结你看到的 DNAT 规则就是 宿主机端口映射到容器端口的秘密,让容器对外可访问。
配合 MASQUERADE/SNAT 规则,又实现了容器主动访问外网。
这就是 Docker 网络的核心工作机制:NAT + IP 转发 + iptables 规则。
容器转发性能损耗
理论上,容器的端口映射和 NAT 会引入 轻微的性能损耗,但实际影响取决于场景和流量大小。
原因
额外的网络栈处理
- 当容器访问外网,或者外部访问容器时,数据包必须经过宿主机的 iptables NAT 处理(DNAT/SNAT)。
- 这个过程需要 Linux 内核修改数据包头部,并做路由判断,相比直接服务监听在宿主机端口上多了一步处理。
桥接网络
- 默认 Docker 使用 docker0 网桥,容器的虚拟网卡(veth)通过网桥转发数据包。
- 数据包从容器 → veth → docker0 → iptables → 外网,需要经过几次内核层面转发,比直接在宿主机端口监听多了几个环节。
网络命名空间隔离
- 容器在独立网络命名空间内,需要额外做 NAT 和路由转换。
- 这种隔离提供了安全性,但也增加了内核处理开销。
实际损耗
- 轻量服务(HTTP 请求量不高,单机访问):
- 性能损耗可以忽略不计,通常 <1%~5%。
- 高性能或大流量服务(如 CDN、视频流、大量 TCP 连接):
- NAT + 桥接网络可能成为瓶颈,需要优化。
性能优化方式
Host 网络模式
- 启动容器时使用
--network=host,容器直接使用宿主机网络栈 - 避免 NAT/Docker 网桥,性能几乎和直接在宿主机部署服务相同
合理的端口映射策略
- 尽量减少不必要的端口转发
- 高性能服务可直接在宿主机监听端口,或者使用 host 模式
容器网络插件优化
- 使用 CNI 插件或 macvlan,让容器直接拥有物理网络 IP
- 减少内核 NAT 和桥接开销
总结
| 部署方式 | 性能 | 说明 |
|---|---|---|
| 直接在宿主机部署 | 最高 | 数据包直接处理,没有 NAT 或桥接开销 |
| 容器 + 默认桥接 + NAT | 略低 | 多一层 NAT + veth 桥接,轻微性能损耗 |
| 容器 + host 网络模式 | 接近宿主机 | 容器直接用宿主机网络栈,几乎无额外开销 |
损耗来源
- NAT 处理:容器端口映射(DNAT/SNAT/MASQUERADE)需要内核修改数据包头部,增加少量 CPU 开销。
- 桥接网络:数据包从容器虚拟网卡 → docker0 网桥 → iptables → 外网,多了几个内核层处理环节。
- 网络命名空间隔离:容器独立的网络栈增加转发和路由开销。
实际影响
- 轻量服务(普通 Web 或后台服务):性能损耗微乎其微,通常 <5%,可忽略。
- 高吞吐量或高并发服务(视频流、大量 TCP 连接):NAT 与桥接可能成为瓶颈,需要优化。
结论:
- 对一般 Web 服务或后台服务,性能差异可以忽略
- 对高吞吐量、高并发场景,容器 NAT 和桥接网络可能成为瓶颈,需要 host 模式或其他网络优化方案
- 容器端口转发会带来轻微性能损耗,但对于大多数应用可以忽略;只有在高并发、大流量场景下,才需要通过 host 网络或其他网络优化方案来降低开销。
容器 NAT/桥接网络确实带来轻微性能损耗,但换来了 灵活的网络管理、服务隔离和部署便利。
对大多数应用而言,这种损耗完全可以接受,而收益非常显著。
自定义网桥
除了默认的 docker0 网桥,用户也可以创建 自定义网桥,让容器连接到指定的网络环境中。
指定 Docker 使用的网桥
在启动 Docker 服务时,可以通过参数指定网桥:
dockerd -b BRIDGE # 或
dockerd --bridge=BRIDGE如果 Docker 服务已经运行,需要先停止服务并删除旧的默认网桥。
停止 Docker 并删除默认网桥
sudo systemctl stop docker # 停止 Docker 服务
sudo ip link set dev docker0 down # 将 docker0 接口关闭
sudo brctl delbr docker0 # 删除 docker0 网桥注意:删除网桥会断开所有使用该网桥的容器,请确保容器已经停止或迁移。
创建自定义网桥
创建网桥接口 bridge0:
sudo brctl addbr bridge0给网桥分配 IP 地址:
sudo ip addr add 192.168.5.1/24 dev bridge0启动网桥:
sudo ip link set dev bridge0 up查看网桥状态:
ip addr show bridge0示例输出:
4: bridge0: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state UP group default
link/ether 66:38:d0:0d:76:18 brd ff:ff:ff:ff:ff:ff
inet 192.168.5.1/24 scope global bridge0
valid_lft forever preferred_lft forever配置 Docker 使用自定义网桥
编辑 Docker 配置文件 /etc/docker/daemon.json:
{
"bridge": "bridge0"
}保存后,启动 Docker:
sudo systemctl start docker验证容器是否连接到自定义网桥
新建一个容器:
docker run -it --rm alpine sh容器内查看 IP 地址和路由:
ip addr
ip route宿主机查看网桥信息:
brctl show可以看到新建容器已经连接到 bridge0,分配了该网段的 IP。
自定义网桥的作用
网络隔离与拓扑管理
- 隔离容器网络:通过自定义网桥,你可以把一组容器放在独立的网络里,互相之间或与默认网桥的容器隔离。
- 自定义拓扑:可以为不同应用或服务创建不同网段,便于管理和安全策略的实施。
- 避免冲突:默认
docker0使用 172.17.0.0/16 网段,自定义网桥可以使用其他私有网段,防止与宿主机或其他网络冲突。
自定义 IP 和路由
- 指定 IP 段:创建自定义网桥时可以分配特定的网段(如 192.168.5.0/24),容器获得的 IP 在该网段内。
- 灵活路由:可以结合宿主机路由策略,控制容器间或容器对外访问的路径。
- 便于网络规划:在多服务或多租户环境下,IP 管理更清晰,可避免地址冲突和混乱。
安全控制
- 控制互访:不同网桥的容器默认不能直接互相访问,可以配合
-icc=false或防火墙策略严格控制通信。 - 精细权限:只允许特定网桥内的容器互相通信,实现更精细的访问控制。
提高管理便利性
- 多环境部署:可为不同应用环境(如开发、测试、生产)创建独立网桥,避免互相干扰。
- 便于监控:每个网桥可以单独监控流量、连接和端口使用情况。
- 方便迁移和扩容:容器可以快速挂载到指定网桥,不影响其他服务网络。
总结
自定义网桥的核心作用是隔离网络、灵活管理 IP 和路由、提高安全性和便捷性,它让 Docker 容器网络更可控、可规划,并且适用于多租户、复杂服务和生产环境。
多个自定义网桥
在 Docker 中,你可以创建 多个自定义网桥,并让不同容器连接到不同的网桥,从而实现容器间的 网络隔离。
多网桥支持
- Docker 不只支持默认
docker0,还可以通过brctl或 Docker 网络命令创建多个网桥。 - 每个网桥都是一个独立的 L2 网络,拥有自己的 IP 网段。
例如:
# 创建两个自定义网桥
sudo brctl addbr bridgeA
sudo ip addr add 192.168.10.1/24 dev bridgeA
sudo ip link set dev bridgeA up
sudo brctl addbr bridgeB
sudo ip addr add 192.168.20.1/24 dev bridgeB
sudo ip link set dev bridgeB up容器连接不同网桥
在启动容器时,指定使用哪一个网桥:
# 容器1连接 bridgeA
docker run -dit --name container1 --network=bridgeA alpine
# 容器2连接 bridgeB
docker run -dit --name container2 --network=bridgeB alpine结果:
- 容器1只在 bridgeA 网络内通信
- 容器2只在 bridgeB 网络内通信
- 默认情况下,桥间互不访问,实现了 网络隔离
网络隔离的效果
不同网桥的容器:
- IP 网段不同
- 默认不可以互相 ping 或访问端口
可以通过防火墙、--link 或自定义路由策略实现必要的跨网桥访问。
总结
Docker 支持多个网桥,每个网桥独立管理 IP 和流量。将容器分配到不同网桥,可以实现 网络隔离,提高安全性和网络管理可控性。
同时,你可以灵活配置 NAT、端口映射或防火墙规则,实现精细化访问控制。
跨网桥通信
Docker 容器点到点(P2P)网络连接
在默认情况下,Docker 会将所有容器连接到一个虚拟子网中(通常是 docker0 网桥)。
这意味着容器之间的通信都需要经过主机上的桥接设备转发。
然而,有时用户希望让两个容器直接通信,而不是通过 docker0 转发。 例如:
- 构建高性能容器间通信通道;
- 进行网络实验或自定义拓扑;
- 测试自定义协议或非 IP 网络环境。
此时,就可以通过 Linux veth(虚拟以太网对) 来实现“点到点”连接(point-to-point link)。
实现思路
veth pair(虚拟以太网对)是一对成对存在的虚拟网络接口:
- 一端发送的数据会从另一端接收;
- 它们可以被放入不同的网络命名空间(netns),从而实现两个容器之间的直连。
Docker 容器的网络环境本质上也是一个独立的 network namespace, 所以我们可以:
- 启动两个容器(不使用默认网桥);
- 创建一对 veth 接口;
- 将这对接口分别放入两个容器的网络命名空间;
- 配置 IP 地址与路由。
操作步骤
启动两个不带网络的容器
docker run -it --rm --net=none base /bin/bash
root@1f1f4c1f931a:/#
docker run -it --rm --net=none base /bin/bash
root@12e343489d2f:/#--net=none 表示容器启动后没有任何网络接口(除了 lo),方便我们手动配置。
获取容器的进程号(PID)
docker inspect -f '{{.State.Pid}}' 1f1f4c1f931a
# 输出:2989
docker inspect -f '{{.State.Pid}}' 12e343489d2f
# 输出:3004每个容器都有独立的网络命名空间,可以通过 /proc/<PID>/ns/net 访问。
将容器的网络命名空间挂载到系统可见位置
sudo mkdir -p /var/run/netns
sudo ln -s /proc/2989/ns/net /var/run/netns/2989
sudo ln -s /proc/3004/ns/net /var/run/netns/3004这样我们就可以使用 ip netns exec 命令直接操作容器网络。
创建一对 veth 虚拟接口
sudo ip link add A type veth peer name B此时系统中出现了两张网络卡片:
AB
它们是连通的,一端发包另一端就能收到。
将接口放入容器网络命名空间并配置 IP
# 连接到容器 1
sudo ip link set A netns 2989
sudo ip netns exec 2989 ip addr add 10.1.1.1/32 dev A
sudo ip netns exec 2989 ip link set A up
sudo ip netns exec 2989 ip route add 10.1.1.2/32 dev A
# 连接到容器 2
sudo ip link set B netns 3004
sudo ip netns exec 3004 ip addr add 10.1.1.2/32 dev B
sudo ip netns exec 3004 ip link set B up
sudo ip netns exec 3004 ip route add 10.1.1.1/32 dev B验证连接
在任意一方容器中执行
ping 10.1.1.2若可以连通,即表示点到点网络成功建立。
拓展:保留原有网络 + 直连通道
如果在启动容器时不加 --net=none, 例如:
docker run -it --rm base /bin/bash则容器除了默认连接到 docker0 网桥外,还可以额外通过上述 veth 对建立点到点链路,实现双网络接口的效果:既能访问外网,又能和特定容器直连通信
安全提示:使用 --icc=false 的替代方案
如果只是为了限制容器之间的互访,无需创建复杂链路,可以直接在 Docker 启动参数中设置:
--icc=false --iptables=true这样容器间默认禁止互访,仅允许显式授权的端口访问,这是比手动隔离更简洁的安全方案。